Eric-Tuan Le*
University College London
Edward Bartrum*
University College London, Alan Turing Institute
Iasonas Kokkinos
University College London
*Equal contribution
Disentangling Shape, Pose and Appearance through 3D Morphable Image and Geometry Generation
*Equal contribution
We introduce StyleMorph, a 3D-aware generative model that disentangles 3D shape, camera pose, object appearance, and background appearance for high quality image synthesis. We account for shape variability by morphing a canonical 3D object template, effectively learning a 3D morphable model in an entirely unsupervised manner through backprop. We chain 3D morphable modelling with deferred neural rendering by performing an implicit surface rendering of “Template Object Coordinates” (TOCS), which can be understood as an unsupervised counterpart to UV maps. This provides a detailed 2D TOCS map signal that reflects the compounded geometric effects of non-rigid shape variation, camera pose, and perspective projection. We combine 2D TOCS maps with an independent appearance code to condition a StyleGAN-based deferred neural rendering (DNR) network for foreground image (object) synthesis; we use a separate code for background synthesis and do late fusion to deliver the final result. We show competitive synthesis results on 4 datasets (FFHQ faces, AFHQ Cats, Dogs, Wild), while achieving the joint disentanglement of shape, pose, object and background texture.
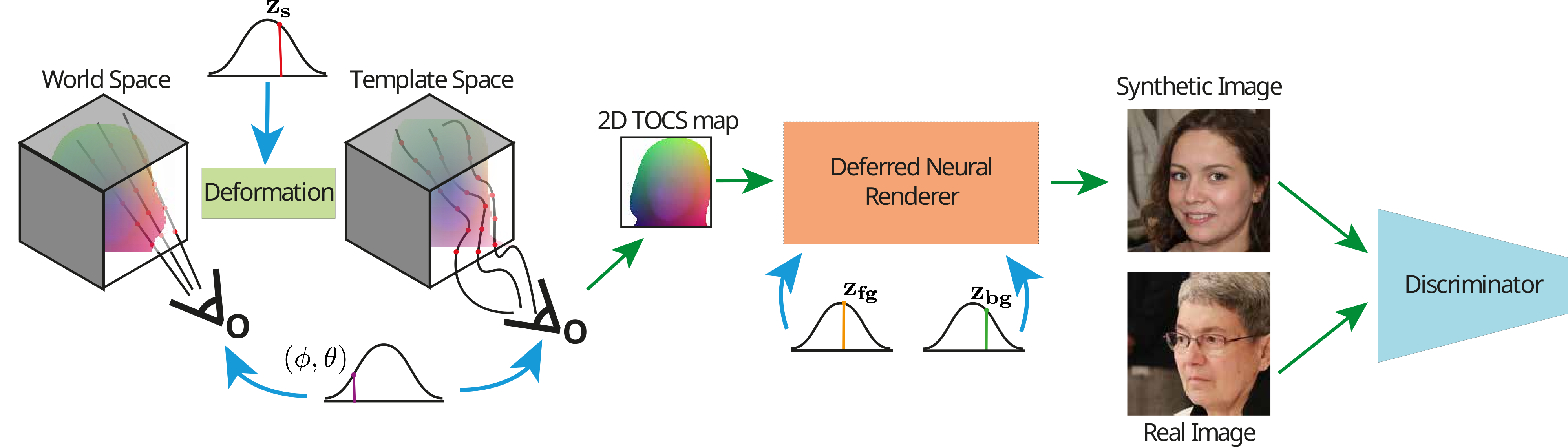
Our method trains on an unstructured collection of RGB images. We learn a generative model that (i) disentangles camera, shape and foreground/background appearance, (ii) expresses shape variability through deformations and (iii) efficiently generates high resolution, realistic images.
We model canonical shape as a signed distance function in template space, and warp it using a non-rigid shape deformation ![]() . We render template coordinates using camera pose (φ, θ),
and perspective projection, to produce a rendered 2D Template Object Coordinate System (TOCS). The 2D TOCS maps are passed into a Deferred Neural Rendering network together with latent codes for foreground
and background appearance (
. We render template coordinates using camera pose (φ, θ),
and perspective projection, to produce a rendered 2D Template Object Coordinate System (TOCS). The 2D TOCS maps are passed into a Deferred Neural Rendering network together with latent codes for foreground
and background appearance (![]() ,
, ![]() ) to produce high-resolution photorrealistic images trained by a discriminator network.
) to produce high-resolution photorrealistic images trained by a discriminator network.
We warp camera rays from world to template space and use differentiable rendering to produce “Template Object Coordinates” (TOCS). TOCS maps provide dense image-to-template object correspondences. They reflect the compounded effects of non-rigid shape, pose, and perspective projection, but are appearance-agnostic. They feed into a Deferred Neural Renderer together with latent codes for foreground and background appearance to produce photorrealistic images.
Drag the slider to reveal the TOCS maps underlying our image synthesis
Our approach uses separate latent codes for shape, background and foreground appearance. By varying codes in one latent space and holding the others fixed, our model exhibits disentangled synthesis with independent control over each factor of variation, in addition to 3D-consistent camera pose control. Despite our additional disentanglement and template-based shape model constraints, our image synthesis quality is competitive with the state-of-the-art 3D-aware models.
Below we show interpolation results from varying each factor of control on FFHQ and AFHQ datasets.
"@inproceedings{
le2023stylemorph,
title={StyleMorph: Disentangled 3D-Aware
Image Synthesis with a 3D Morphable Style{GAN}},
author={Eric-Tuan Le and Edward Bartrum
and Iasonas Kokkinos},
booktitle={The Eleventh International Conference
on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=Ojpb1y8jflw}
}"



All models described in this research were trained using Baskerville Tier 2 HPC service (funded by EPSRC Grant EP/T022221/1 and is operated by Advanced Research Computing at the University of Birmingham), and JADE: Joint Academic Data science Endeavour - 2 under the EPSRC Grant EP/T022205/1, & The Alan Turing Institute under EPSRC grant EP/N510129/1. We are grateful to Gabriel Browstow and Niloy Mitra for providing useful discussions and insights.